
Big data e analytics nelle aziende manifatturiere per il miglioramento dei processi decisionali
Introduzione
Le tecnologie odierne mettono a disposizione innumerevoli flussi di dati.
La mole dei dati generata è aumentata di 50 volte dal 2010 al 2020. La generazione di dati per ciascun essere umano nel 2020 è stata stimata nel 2019 di 1,7 Mbyte/s per raggiungere complessivamente 44 ZB in tutto il 2020. Queste previsioni sono da Fonte IDC, prima della pandemia, per cui i risultati sono sottostimati.
Oggi qualunque apparecchiatura leggermente complessa con cui abbiamo a che fare, dal più piccolo elettrodomestico alle automobili, dai cellulari ai computer, dalle più semplici macchine per l’industria ai grandi impianti robotizzati, oltre a svolgere le funzioni primarie richieste dal cliente, per i quali sono stati progettati, mettono a disposizione moltissime altre informazioni.
Queste informazioni sono di molteplice natura: informazioni di sicurezza quali allarmi e warning per l’utente, misurazioni, ad esempio sui manufatti realizzati, o anche semplici registrazione di comportamenti e modalità di utilizzo dell’apparecchiatura quali ore di utilizzo, modalità di impiego, numero delle lavorazioni, numero delle interruzioni.
Esiste poi una innumerevole serie di informazioni, provenienti sempre da dispositivi elettronici, che non registrano l’utilizzo del dispositivo stesso, ma rappresentano i comportamenti, le abitudini, lo stato di salute, fino anche le opinioni e i gusti degli utenti del dispositivo. Sappiamo che anche questi dati sono di grandissimo interesse, anzi sono tra i più ricercati.
I dati rappresentano quindi, secondo una espressione diffusa, il “petrolio” di oggi.
Perché utilizzare i dati?
Sempre di più l’imprenditore e il Top Management ricerca soluzioni espressamente dedicate all’analisi del dato per mettere in campo azioni che portino a:
- Conoscenza dei propri processi
- Riduzione dei costi
- Conoscenza dei clienti
- Sviluppo di nuovi servizi
Cosi la analisi dei dati porta a sviluppare azioni per il controllo del processo produttivo, di manutenzione predittiva degli impianti per evitare i fermi macchina e di vero e proprio CRM (Customer Relationship Management): rapporto con i clienti, customer experience per operazioni di marketing e miglioramento del processo di vendita.
Il dato e l’informazione che il dato porta diventa quindi uno degli strumenti principali di guida ai processi decisionali all’interno delle organizzazioni. Moltissime aziende hanno già sperimentato che il sapere utilizzare i dati che provengono dai propri processi porta vantaggio competitivo.
Secondo le previsioni di IDC, entro il 2022 un terzo delle grandi aziende avvierà iniziative formali di alfabetizzazione dei dati tra i propri dipendenti per promuovere una cultura data-driven e contrastare la disinformazione. Ed entro il 2023, il 70% delle grandi aziende impiegherà metriche per misurare il valore generato dai dati, migliorando così i processi decisionali e l’allocazione delle risorse interne in tutta l’organizzazione.
La questione ora è proprio questa. Come organizzarsi per avere una struttura di dati efficiente e soprattutto come utilizzare l’innumerevole flusso di dati che sono già a disposizione?
Cosa sono i “BIG DATA”
Secondo una definizione del McKinsey Global Institute: “Un sistema di Big Data si riferisce a dataset la cui taglia/volume è talmente grande che eccede la capacità dei sistemi di database tradizionali di catturare, immagazzinare, gestire ed analizzare”.
I Big Data sono quindi un flusso di dati che si caratterizzano per Volumi, Varietà e Velocità. È il modello delle 3V.
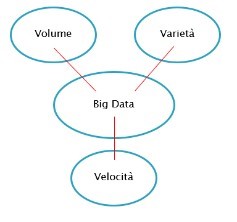
Volume: rappresenta la quantità di dati strutturati e non strutturati
Varietà: dati di diversa tipologia quali database relazionali, ma anche file di testo generati dalle macchine industriali o i log di web server o dei firewall
Velocità: Velocità della generazione dei dati, dati a disposizione Real Time
La struttura di un modello BIG DATA
La struttura di un modello di BIG DATA, da qualunque sistema hardware e software possa essere implementato, può essere rappresentato dai livelli seguenti:
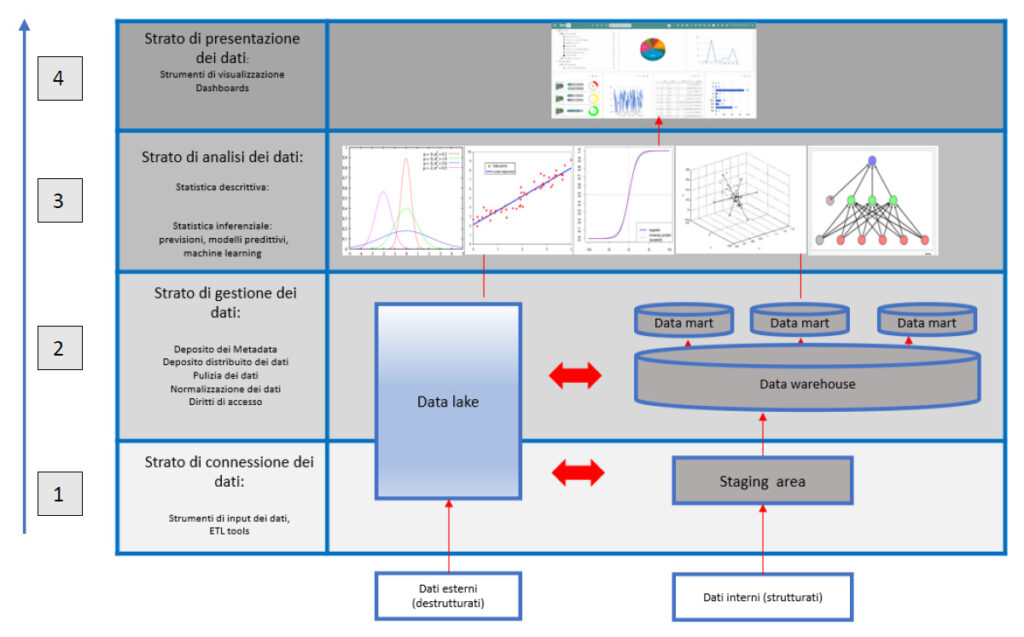
LA STRUTTURA VA UTILIZZATA DAL BASSO VERSO L’ALTO
Origine dei dati e strato di connessione
Si possono distinguere 2 tipologie di dati:
- Dati che provengono da fonti interne all’azienda e sono quindi per loro natura strutturati (ad esempio database). In genere sono dati a disposizione nei sistemi aziendali (ERP, MES, WMS) oppure hanno la loro origine dalle macchine operative che trasmettono al data warehouse aziendale tutte le informazioni in modo strutturato.
- Dati che provengono da fonti esterne e sono spesso destrutturati, ad esempio email o file di testo.
I dati sono immessi nel “Sistema” attraverso la fase di Input dei dati (Ingestion) ossia attraverso opportuni strumenti di ETL (Extract: estrazione dei dati dalla fonte; Transform: trasformazione dei dati: Load: caricamento dei dati nelle strutture finali).
Strato di gestione dei dati
I dati sono immagazzinati all’interno del Sistema con opportune politiche di diritti di accesso. I dati possono essere grezzi e depositati come alla fonte nel Data Lake, oppure opportunamente normalizzati, puliti e strutturati, terminare nel Data Warehouse aziendale. È evidente che la qualità del dato è fondamentale per le successive analisi, in quanto un dato che non porta una corretta “informazione” genererà modelli predittivi che hanno una scarsa capacità di predizione.
La qualità del dato è misurata in termini di:
- Integrità: l’informazione raccolta rappresenta davvero la caratteristica che si vuole indagare?
- Accuracy: una misura, o la media di misure, è in accordo con un valore standard di riferimento (si parla anche di BIAS)?
- Validità: ogni misura rispetta le regole ed i vincoli definiti dalla organizzazione, ed in particolare nei sistemi informatici definisce le regole di validità nel sistema considerato?
- Consistenza: una serie di misure è coerente in tutto il sistema?
- Uniformità: i dati sono registrati utilizzando lo stesso metodo?
Strato di analisi del dato
I dati che già hanno subito l’operazione di pulizia (cleaning) sono pronti per l’analisi. Le tecniche di analisi sono molteplici e utilizzano in grande misura strumenti di tipo statistico. Alcuni esempi sono: test statistici per verificare l’intervallo di confidenza delle conclusioni prese, analisi della correlazione esistente tra flussi di dati, utilizzando strumenti appropriati quali studi di regressione (lineare, logistica ecc), studio delle componenti principali (PCA) per eliminare dati secondari.
È necessario che le organizzazioni si affidino ai “Data scientists”, esperti che conoscano l’utilizzo di tecniche statistiche evolute. È comunque necessario che anche il Management abbia una conoscenza di base di questi strumenti in quanto deve essere in grado di valutare i risultati presentati dagli “scienziati del dato”.
L’obiettivo dell’analisi dei dati è estrarre informazioni importanti sullo “storico”, cioè su quello che è successo, ma soprattutto di costruire un modello predittivo che possa favorire il processo decisionale per il futuro, tenendo conto dei fattori di costo.
Ad esempio l’analisi del trend di un processo produttivo può evidenziare un possibile fuori controllo con conseguente “fuori specifica”, prima che questo accada e determinare azioni di manutenzione preventiva.
Il modello predittivo (es machine learning) deve essere quindi testato con dati reali. Esistono molti metodi di test per la validazione dei modelli predittivi, ad esempio i modelli di cross validation che utilizzano set di dati per il training degli algoritmi e set di dati per il test di questi stessi algoritmi.
Strato di presentazione dei dati
I dati sono presentati al supervisor e al management in modo sintetico, con diversi livelli di aggregazione. Si costruisce così la dashboard, il “cruscotto” degli indicatori, che consente ai responsabili di avere il monitoraggio delle attività e prendere le decisioni opportune. Nei casi più evoluti, algoritmi di machine learning sono in grado di suggerire le decisioni da prendere.
L’implementazione del sistema: l’approccio
Nell’applicazione di un sistema di Big Data è possibile fare riferimento a metodologie di project management.
Tra le varie metodologie, il sistema DMAIC process (Define, Measure, Analyze, Improve, Control), proveniente dalla “filosofia” SIX SIGMA, ben si adatta alle fasi sopra descritte.
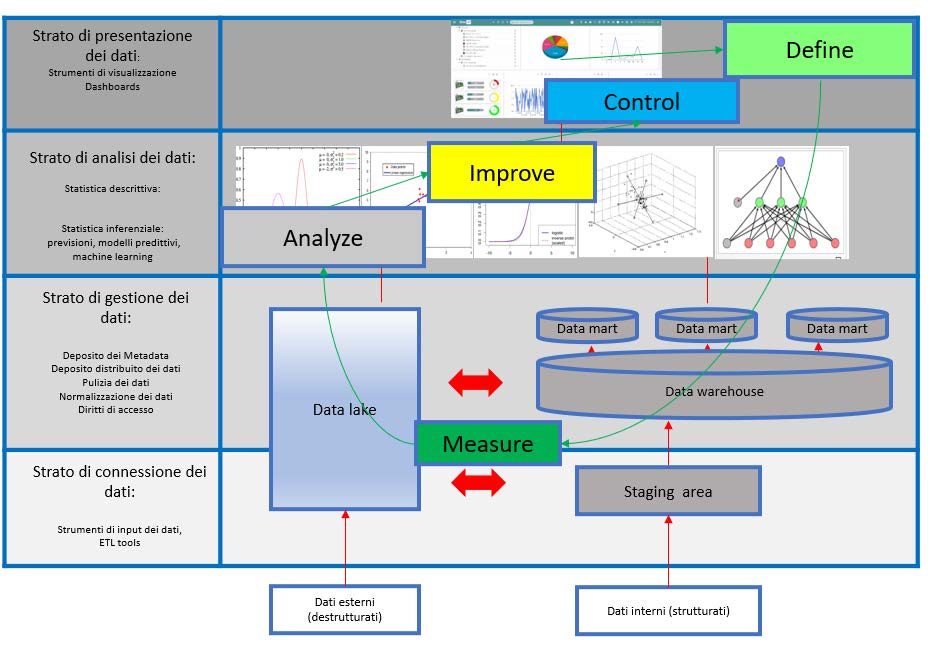
Define
È il punto di inizio. Si tratta di definire quali sono gli output desiderati del sistema. La scelta della struttura Big Data dipende dagli obiettivi e dalla strategia aziendale definita dal Top Management. in questa fase si definiscono le informazioni che il sistema Big Data dovrà fornire al management. I dati sono generalmente forniti con diversi livelli di aggregazione secondo il destinatario (personale operativo, supervisor o manager).
Measure
La definizione della qualità delle fonti di informazione non è un concetto assoluto, ma dipende dagli output attesi. La qualità del dato non è solo un fatto tecnico, ma spesso dipende dalla struttura organizzativa, quindi i limiti di qualità dei dati devono essere noti al Management e gestiti.
Analyze
Il Management deve conoscere le basi delle analisi statistiche per poter valutare i risultati presentati dai Data Scientist. Ogni ipotesi statistica è accompagnata dalla valutazione del rischio di errore (alpha e beta). Il Management deve definire le soglie di rischio (confidenza) in funzione degli obiettivi.
Improve
In questa fase si usano i risultati per fare previsioni e fare scelte. I modelli previsionali devono essere affiancati dalla definizione delle Funzioni Costo o dalle funzioni di perdita (ad esempio il modello di Taguchi), i cui parametri sono legati agli obiettivi aziendali. Il Management deve utilizzare le previsioni fornite dai modelli per definire soluzioni economiche ottimali. Quindi si deve ottimizzare la funzione costo insieme con la soluzione tecnica.
Control
Tutte le condizioni al contorno, i parametri e i dati di ingresso sono soggetti a cambiamenti per cui è necessario che sia pianificata una rivalutazione periodica dei modelli per garantire la qualità della predizione.
Un esempio di applicazione reale
Vengono omessi, per motivi di riservatezza, il nome dell’azienda e le caratteristiche reali del processo.
Define
In questa fase fondamentale è assolutamente indispensabile definire l’obiettivo del progetto in termini numerici e il perimetro del progetto stesso.
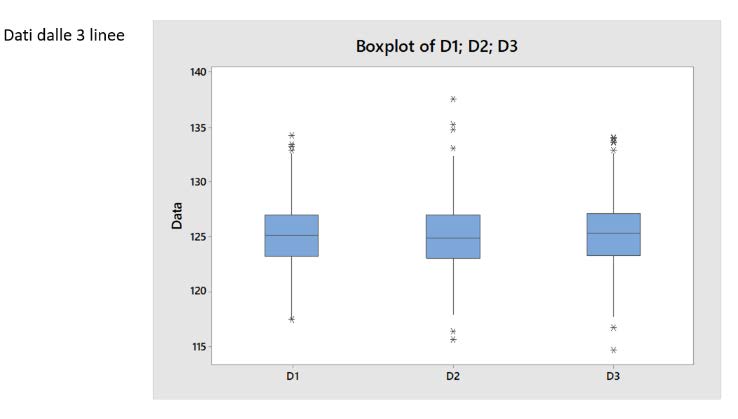
PROBLEM STATEMENT: Utilizzare i dati raccolti da 3 macchine per estrarre le informazioni relative all’andamento del processo.
PROJECT SCOPE (perimetro del progetto): Il progetto si applica alle le macchine D1, D2, D3 in produzione ed è relativo al processo di riempimento, con la corretta quantità Z, del contenitore, con le caratteristiche P1, P2 …
PROJECT GOAL: definire i criteri di valutazione delle performance del processo per le caratteristiche del prodotto, in termini di:
- Indicatori di un processo sotto controllo
- Capability del processo di rispettare le specifiche di prodotto
- Definizione delle performance dei singoli parametri di processo per correlarli alla specifica finale del prodotto (cause ed effetti)
- Generare un sistema di reporting multilivello basato sull’attuale sistema aziendale, che si serva dei dati presenti sulla local repository dello stabilimento di riferimento
- ecc
Measure
Identificazione del sistema dei dati occorrenti, del sistema di misura e di pulizia dei dati da estrarre:
Analyze
In questa fase si analizzano i dati provenienti dalle macchine per identificare correlazioni e diseguaglianze:
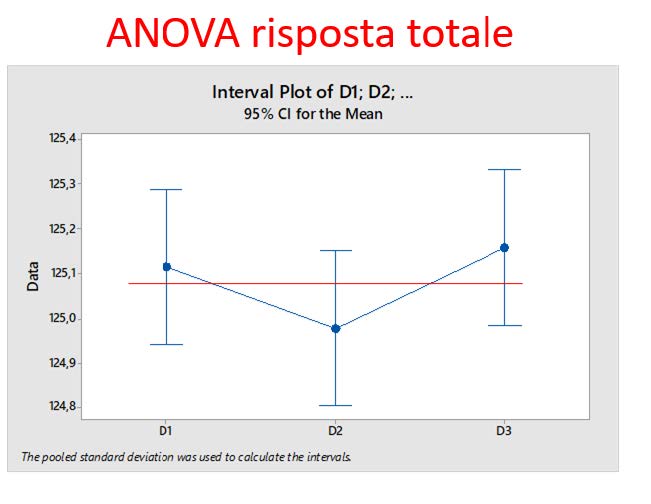
Improve
Questa fase insieme con la precedente permette di verificare se esiste una relazione tra i parametri di ingresso Pi e l’uscita del processo Z.
Determinata la risposta ottimale del sistema sotto forma di indicatore di capability di processo (Cpkmin = Ppkmin= 1,5), è possibile individuare i valori dei parametri di ingresso che consentono la risposta ottimale. Si noti che i parametri di ingresso sono a loro volta parametri di uscita di processi produttivi precedenti.
Nelle figure di sotto sono indicate le Process capability dei processi P… e del processo di uscita finale Z.
E’ indispensabile previlegiare la soluzione a costo minimo che sia tecnicamente perseguibile.
Per questo nell’esempio illustrato si è utilizzata la funzione obiettivo, che minimizza il costo complessivo.
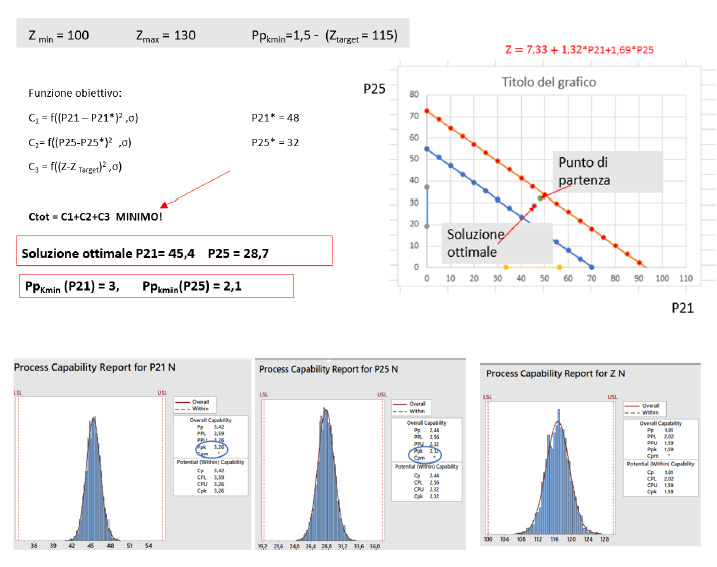
Control
Una volta individuati i parametri ottimali, questi parametri devono essere mantenuti. In questa fase si considerano gli strumenti che permettono di tenere sotto controllo i processi produttivi dei parametri Pi. E’ possibile per esempio ricorrere agli strumenti tradizionali dell’SPC (Controllo statistico di processo).
Avendo a disposizione la grande quantità di dati che i sistemi di BIG DATA mettono a disposizione e i software di analisi sempre più potenti si possono estrarre le informazioni proprie delle carte di controllo in modo ottimale, senza la necessità della compilazione manuale delle stesse. Ora finalmente uno strumento “tradizionale” può essere utilizzato in tutta la sua potenzialità.
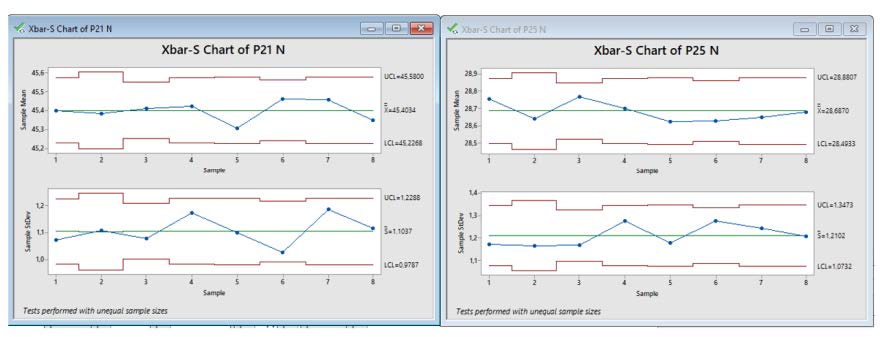
Conclusioni
È opportuno riepilogare quanto è necessario per implementare un sistema di Big Data:
- Individuare le competenze necessarie
- Definire la struttura del sistema e le tecnologie per implementare il sistema
- Individuare i dati necessari e le fonti di questi dati
- Individuare i metodi per l’ingestion di questi dati nel sistema e per la loro elaborazione
- Individuare i metodi di analisi e di realizzazione di modelli predittivi
- Testare i modelli di previsione, fare le scelte
- Governare il sistema pianificando rivalutazioni periodiche
Ma prima di tutto questo, prima di affidarsi ai data scientist e prima ancora di investire in piattaforme tecnologiche hardware e software, si deve partire dal fondo, cioè DEFINIRE esattamente i punti di arrivo, cioè gli output del sistema!
Saranno gli output desiderati a definire la struttura anche tecnologica del sistema di Big Data dell’azienda.
Articolo a cura di Ezio Gaiani

Ezio Gaiani, nel 1989, si è laureato in Ingegneria elettronica col massimo dei voti presso la Facoltà di Ingegneria dell’Università di Bologna.
Dopo la laurea ha iniziato un’intensa attività lavorativa, in successione, presso tre primarie Aziende dell’area bolognese, prima come Responsabile della Qualità, poi come Responsabile della Produzione e della Logistica.
La FAW l’ha validato, per le aree di competenza, come formatore dei fornitori della FORD di Colonia (Germania).
Dal 2015 è Consulente senior presso la CUBO Società di Consulenza Aziendale di Bologna, svolgendo interventi nella Formazione e nella Consulenza nei settori Produzione – Logistica – Qualità.
Ha infine acquisito una forte esperienza, come consulente e formatore, nella gestione dei Big Data.





