
Intelligenza Artificiale in pratica
Si parla tanto di Intelligenza Artificiale (IA), ma è davvero utilizzata nelle aziende, e come?
A questo proposito, Bill Ruh, CEO di GE Digital e chief digital officer di GE intervistato a proposito dell’utilizzo aziendale dell’Intelligenza Artificiale dice: “Quando vado alle conferenze e il presentatore chiede quante persone hanno progetti di Intelligenza Artificiale?, tutti alzano la mano, ma quando poi chiede quante persone stanno facendo dei progetti pilota? se ne alzano forse la metà, e quasi nessuno è in produzione.”[1]
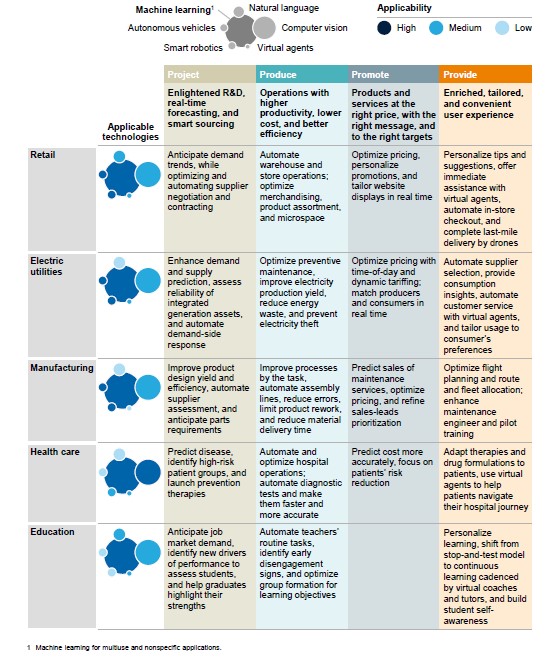
Il fatto è che ci sono in giro molti progetti di Machine Learning (e forse ancora di più di “Deep Learning” vedremo dopo perché) ma pochi di Intelligenza Artificiale a tutto tondo. Negli anni trascorsi gli investimenti in strumenti generici di “Machine Learning” sono stati significativamente maggiori rispetto alle altre tecnologie (fig. 1) e questo a causa dell’applicabilità cross-industry di queste tecnologie (fig. 2)[2].
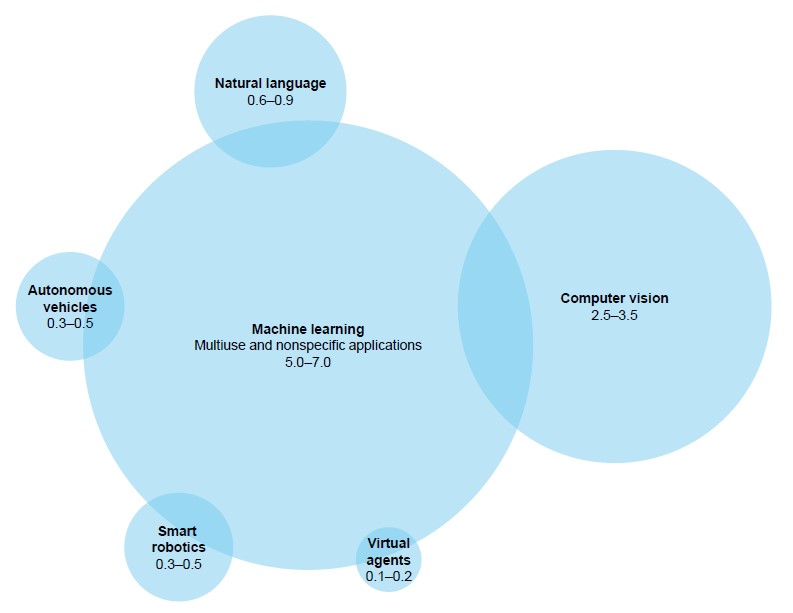
Inoltre, le tecnologie di “Deep Learning” hanno bisogno di un livello di personalizzazione relativamente basso per essere utilizzate in applicazioni e settori diversi.
I maggiori investimenti, e quindi il maggior utilizzo di queste tecnologie, hanno fatto sì che oggi IA, “Machine Learning” e “Deep Learning” vengano spesso utilizzati come sinonimi anche se non sono la stessa cosa: l’apprendimento automatico (“Machine Learning”) è infatti solo una parte dell’Intelligenza Artificiale e, a sua volta, il “Deep Learning” è una forma di apprendimento/riconoscimento automatico effettuato usando la tecnologia delle reti neurali a più livelli.
Le reti neurali sono degli algoritmi sviluppati sul modello (fisiologico) del cervello umano. Come il cervello riconosce delle configurazioni o modelli di dati (pattern) e li usa per categorizzare e classificare le informazioni, così fanno i computer utilizzando le reti neurali. Quando incontriamo qualcosa di nuovo, cerchiamo di confrontarlo con un elemento che abbiamo già conosciuto per capire e dare un senso a ciò che abbiamo incontrato, più cose vediamo dello stesso tipo, più cose simili riusciamo a riconoscere: “impariamo” così a individuare oggetti, situazioni, etc….
Grazie alle reti neurali i computer riescono a fare lo stesso, sempre che gli facciamo “incontrare” un numero sufficiente di cose, cioè di informazioni. Di qui la classificazione di questi sistemi all’interno della categoria “Machine Learning”.
Le reti neurali sono in grado di individuare, rapidamente ed economicamente, “configurazioni tipo” di dati (pattern) all’interno di enormi banche dati (da cui l’ampia adozione sull’onda dei Big Data) e quindi riescono ad associare con grande precisione, ma sotto certe condizioni[3], un nuovo insieme di dati ad una “configurazione tipo” o ad un’altra.
Il successo odierno del “Deep Learning”, e quindi (di questa parte) dell’IA, è perciò collegato alla disponibilità della grande mole di dati relativi ad uno stesso fenomeno che sono generate e rese disponibili dai processi di trasformazione digitale e sulle quali i sistemi di IA vengono “addestrati”: es. comportamento del consumatore (siti di e-commerce, app, …), misurazioni del funzionamento di impianti (Internet delle Cose), immagini raccolte tramite i social media (relative a categorie predefinite di soggetti), registrazioni vocali raccolte dai call center, …
Il fatto che l’apprendimento sia considerato uno dei tratti caratteristici dell’intelligenza, rafforza, nell’immaginario collettivo, il considerare i due concetti di “deep Learning” e di IA come sinonimi; tuttavia le applicazioni reali di IA, almeno per il momento utilizzano quasi esclusivamente tecnologie di “Deep Learning”[4].
Per questo illustreremo di seguito l’uso pratico di questa tecnologia, rimandando in nota a singoli casi d’uso.
Il Deep Learning ha bisogno di (tanti) dati
Chiedersi oggi dove l’IA, o meglio il “Deep Learning”, possa essere utilizzato è come se ci fossimo chiesti, quando sono emerse le tecnologie dei database, quali settori ne avrebbero beneficiato; la risposta è: ogni settore.
Infatti, con la digitalizzazione (meglio con la trasformazione digitale) qualsiasi settore dell’economia dispone o disporrà di quantità enormi (e crescenti) di dati utilizzabili da sistemi di “Deep Learning”.
Quindi, per capire dove si possa utilizzare (e si stia utilizzando) questa tecnologia dobbiamo solo chiarire cosa si debba considerare come “dati”. Nel nostro contesto i dati sono tutte le forme di informazione digitalizzabili ovvero che possono essere raccolte e gestite da un computer: dati numerici, testi (o frammenti di testo, es. tweet o post dei social network), registrazioni audio (parlato, musica, rumori), immagini fisse o in movimento (quindi il “Deep Learning” viene usato massicciamente anche nella “machine Vision”, la seconda categoria tecnologica oggetto di investimento: vedi fig.1).
La cosa importante è che i dati siano disponibili in gran quantità e, possibilmente, riferibili ad un dominio ben circoscritto. Ad esempio, un sistema di diagnostica medica per la diagnosi radiografica di problemi al fegato dovrà essere addestrato usando solo radiografie relative al fegato (di esseri umani).
Utilizzare un sistema in un contesto diverso dal contesto in cui è stato “addestrato” può portare ad errori clamorosi. Un esempio per tutti: recentemente, in Cina, un sistema di riconoscimento facciale addestrato a riconoscere i volti delle persone dalle foto e utilizzato per riconoscere le persone mentre attraversano imprudentemente la strada, ha scambiato la foto di una nota imprenditrice (Dong Mingzhu), riportato sul manifesto presente sulla fiancata di un autobus di passaggio, per la persona in carne ed ossa[5]; in altri termini ha scambiato l’immagine di una persona per la stessa in carne ed ossa (fig. 3).

Intelligenza Artificiale e “applicazioni critiche”
La possibilità di incorrere in questo tipo di errore porta a considerare due modi di utilizzare i sistemi di “Deep Learning”, in funzione del rischio associato ad un loro errore nell’interpretazione dei dati che vengono loro presentati quando sono in esercizio:
- Sistemi autonomi rispetto all’intervento umano (i.e. non presidiati: “man out of the loop”): si usano nei casi in cui un possibile errore provoca danni considerati trascurabili in confronto ai benefici ottenuti dal suo funzionamento corretto: il sistema intraprende autonomamente l’azione che considera opportuna nella situazione in cui si trova.
Rientrano in questa categoria i cosiddetti assistenti virtuali[6] e la maggior parte dei chatbots[7] utilizzati nel CRM e nell’e-commerce: se un assistente vocale interpreta la frase “vorrei delle tende da sole” come “vorrei delle tende per il sole” invece che “vorrei delle tende senza accessori” o viceversa, probabilmente non sarà un problema per nessuno, ma solo causa di un sorriso.
Da notare che in generale nei casi di interazione in linguaggio naturale (scritto o parlato) è difficile capire se l’”intelligenza” del sistema sia relativa alla comprensione del testo della richiesta ovvero alla comprensione del significato della richiesta; ad esempio un agente virtuale che si limitasse a trascrivere una richiesta vocale nel testo corrispondente, a sottometterla ad un motore di ricerca e a leggerci le risposte, probabilmente non verrebbe considerato molto “intelligente”, ma prima ce ne dovremmo accorgere…
Comunque anche questi sistemi hanno bisogno di essere “addestrati” per le funzioni per cui si vogliono usare e l’addestramento consiste nello scrivere un piccolo programma definito “Skill” che l’utente può scaricare e installare come un app (a pagamento o meno) [8]; - Sistemi che richiedono la presenza dell’uomo (i.e. presidiati da un operatore: “man in the loop”): si usano nei casi in cui un possibile errore di interpretazione dei dati potrebbe arrecare danni sensibili alle persone e/o di tipo economico: il sistema segnala la situazione ed eventualmente suggerisce l’azione da intraprendere, che comunque rimane sotto la supervisione (e la responsabilità) di un operatore.
Rientrano in questa categoria gli attuali sistemi di guida assistita su strada[9] (ma non quelli che operano in ambienti “gestiti” dove possa essere vietato l’accesso al personale nelle aree in cui operano i veicoli autonomi: magazzini, fabbriche, miniere[10],… per i quali si parla invece di “guida autonoma”), i sistemi di diagnosi medica[11], i sistemi utilizzati da banche e istituti finanziari (per le decisioni non di routine[12]) e tutti i sistemi di supporto alla gestione di sistemi complessi (es. oleodotti[13]).
Per questi sistemi in genere si parla di “augmented intelligence” intendendo il fatto che la tecnologia affianca gli addetti e ne “aumenta l’intelligenza” presentando loro interpretazioni dei dati che essi non sarebbero in grado di fare, vuoi per la quantità di dati da analizzare, vuoi per la difficoltà ad accedervi, vuoi per la rapidità con cui i dati vengono aggiornati.
Un utilizzo particolarmente interessante di questo approccio si ha nel caso in cui siano in esercizio, in parti diverse del mondo, macchinari complessi dello stesso modello o di modelli simili (es. motori) i cui dati siano raccolti e trasmessi ad un sito centrale (utilizzando l’Internet delle cose: IoT). È infatti possibile, in questo modo, segnalare agli operatori locali la necessità di effettuare la manutenzione preventiva del singolo apparato utilizzando i dati storici e capitalizzando l’esperienza di funzionamento di tutta la base installata, cosa impossibile senza le tecnologie: IoT, Big Data e Deep Learning (es. automobili, turbine di aereo[14]).
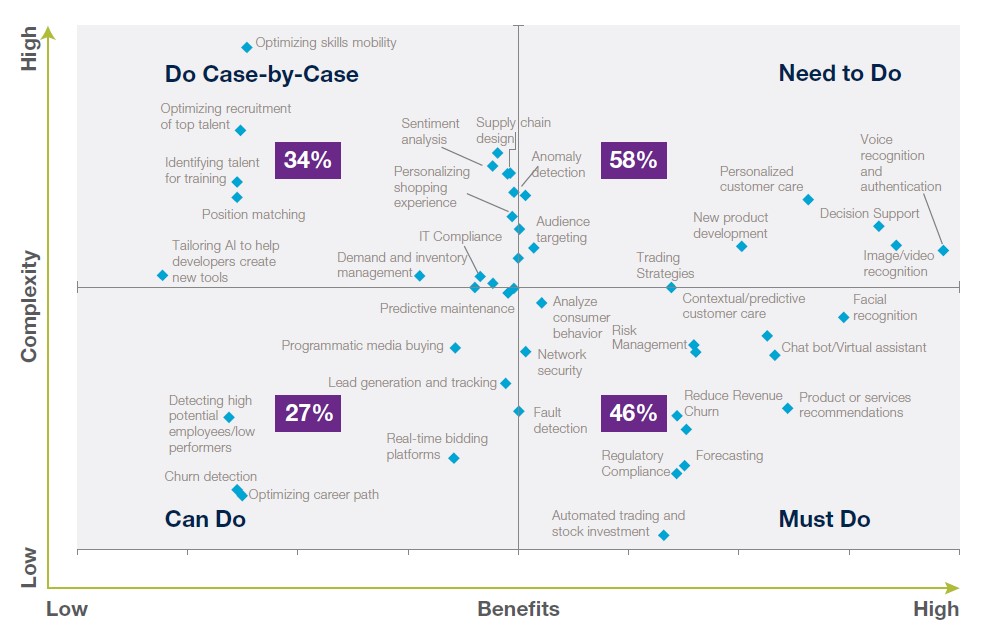
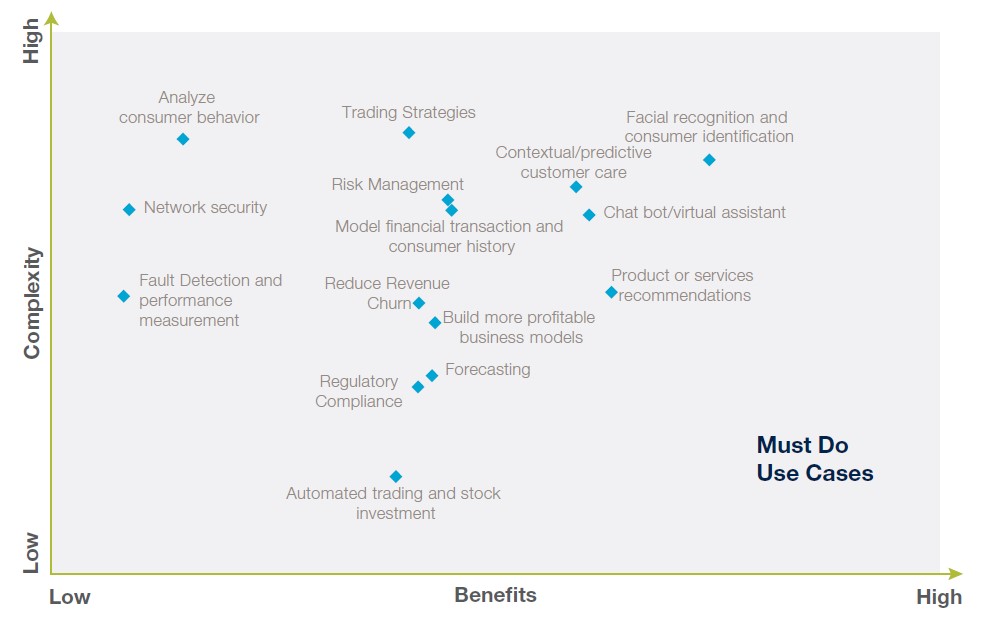
In generale, i potenziali utilizzi delle tecnologie di IA (e non solo di “Deep Learning”) vanno ricercati confrontando benefici vs. complessità/rischi (fig.4) e concentrandosi sugli utilizzi a bassa complessità/rischio (fig.5)[15]. Per gli utilizzi ad alto ritorno e ad alta complessità potrebbe invece essere opportuno/conveniente cercare un approccio di “intelligenza aumentata” e utilizzare la tecnologia in affiancamento al personale.
La necessità di andare oltre il “Deep Learning”
Per addestrare un sistema di “Deep Learning”, oltre a utilizzare molti dati (e di qualità) provenienti da un dominio ben circoscritto e con le attenzioni già dette3, è necessario vigilare a che il sistema non venga tratto in inganno da eventuali “correlazioni spurie”[16] presenti tra i dati.
Si ha una correlazione spuria quando due o più dati hanno variazioni che sembrano dipendere una dall’altra, senza che in realtà ci sia un nesso causale tra di loro. Ad esempio, guardando solo all’andamento dei dati sarebbe possibile individuare una correlazione tra la produzione di burro in Bangladesh e l’andamento di Wall Street[17]… si tratta evidentemente di un caso ovvio (per noi, ma non per un computer) di correlazione spuria. È chiaro come, soprattutto in domini complessi e in presenza di molti dati, il rischio di trovare correlazioni spurie di tipo non ovvio sia molto elevato.
Si noti che questo limite è intrinseco al fatto di basarsi unicamente sull’analisi di pattern di dati raccolti e non dipende dalla maturità della tecnologia di “Deep Learning”, un po’ come per prevedere se un oggetto lasciato andare in un fluido andrà o meno a fondo serve conoscere il principio di Archimede e non basta l’osservazione…
L’unico modo di superare questo problema è integrare la tecnologia di “Deep Learning” con tecniche di ragionamento che utilizzino rappresentazioni simboliche (i.e. modelli) del dominio in grado di identificare relazioni di causa-effetto che spieghino le correlazioni individuate nei dati e che possano quindi scartare le correlazioni spurie (il principio di Archimede nell’esempio citato precedentemente è appunto un modello fisico della realtà).
È bene chiarire che la tecnologia attuale è ancora lontana da questa integrazione e, ad oggi, questo obiettivo può essere raggiunto solo con la supervisione umana[18]. È anche per questo motivo che in situazioni critiche (i.e. dove decisioni sbagliate possono provocare danni) i sistemi di IA sono affiancati da operatori umani.
Conclusione: dobbiamo preoccuparci del successo dell’IA?
Comunque, non è questo il solo motivo per cui è prematuro preoccuparsi del successo dell’IA relativamente alla possibilità per le macchine di sostituire gli uomini.
Una risposta più profonda, tecnicamente parlando, a questa domanda l’ha data Elon Musk: “Per inquadrare questa risposta, lasciatemi descrivere i livelli di maturità dell’IA. Quello di cui abbiamo parlato (anche in questo articolo n.d.r.) è quello che la comunità di ricerca chiama I’IA stretta (“narrow AI”), che è un concetto molto preciso. Pinterest[19] ha costruito qualcosa che può guardare all’interno di un pin e capire cosa raffigura e ciò che gli assomiglia. Questi algoritmi non aiutano Lyft[20] a capire il percorso migliore per andare dal punto A punto B. E gli algoritmi di Lyft non aiutano Freenome[21] a capire se hai il cancro. Sono algoritmi molto specifici per il compito per il quale sono stati scritti ed è per questo che sono chiamati stretti (noi diremmo “verticali” n.d.r.), non sono in grado di generalizzare. Ma, anche, in questi campi verticali ci sono un sacco di cose che le persone possono fare e che gli algoritmi non possono fare.
Il secondo tipo di Intelligenza Artificiale sarebbe l’IA generale. In altre parole, noi possiamo imparare cose nuove, come imparare a pattinare sul ghiaccio, a tenere la contabilità con la partita doppia, e imparare anche il “machine learning” e tante altre cose. Un singolo programma di IA non riesce ancora a fare tutto questo e non c’è consenso nella comunità di ricerca su come si dovrebbe costruire una (singola n.d.r.) macchina/programma che abbia le capacità che hanno i nostri cervelli: le capacità di fare molto rapidamente nuove cose in nuovi domini. Quindi, non siamo nemmeno sulla strada per questo tipo di IA.”[22]
In altre parole, esistono tanti sistemi di IA “verticali” specializzati, ma siamo ancora lontani dalla possibilità, anche teorica, di costruirne uno che sappia svolgere, contemporaneamente, più compiti “verticali” diversi tra di loro.
Come dice Bill Ruh, citato in premessa, con il “Machine Learning” le azioni di un “agente intelligente” sono predeterminate, non da un algoritmo, ma dall’insieme dei dati che gli sono stati presentati fino a quel momento: “With machine learning, the action is not learned; it is predetermined. If you see this pattern, perform this action”.
Note
- [1] ComputerWeekly.com, gennaio 2019 “Top 10 Artificial Intelligence stories of 2018”
- [2] McKinsey Global Institute, giugno 2017 “Artificial Intelligence, The Next Digital Frontier ?”
- [3] Techrepublic “Top 5 ways humans bias machine learning”
- [4] McKInsey Global Institute “Notes from the AI Frontier: insights from hundreds of use cases” pag. 3 “AI, which for the purposes of this paper we characterize as “deep learning” techniques using artificial neural networks”
- [5] “Epic fail del riconoscimento facciale cinese, umilia un’innocente”
- [6] Definizione: “Virtual assistant” esempi: “Top 22 Intelligent Personal Assistants”
- [7] Definizione: “Conversational AI chat-bot”, esempi (mondo bancario):” Meet 11 of the Most Interesting Chatbots in Banking”
- [8] Assistente virtuale di Amazon Alexa: Guida alle Skill di Alexa e Come si costruisce una skill
- [9] Vedere la differenza tra guida automatica e guida assistita (attuale stato dell’arte) in “Autovettura autonoma”
- [10] “In miniera! Ecco dove andranno i primi camion a guida autonoma di Volvo”
- [11] Esempi: “Machine Learning for Medical Diagnostics – 4 Current Applications”
- [12] “Prudential’s Global Head of AI on ‘which algorithm to use and when’”
- [13] “How AI And Machine Learning Are Helping Drive The GE Digital Transformation”
- [14] Volvo:” Volvo Trucks’ Collaboration with SAS Enhances Remote Diagnostics through Advanced Analytics and AI“, Rolls Royce“Rolls-Royce Turns to AI in Bid to Boost Engine Reliability”
- [15] CapGemini: “Turning AI into concrete value”
- [16] Esempi di correlazioni spurie: “Spurious correlations”
- [17] Financial Times “Spurious correlations are kryptonite of Wall St’s AI rush”
- [18] AgendaDigitale.EU “Dove l’intelligenza artificiale sbaglia (ancora), Vetere: “Ecco le prossime frontiere della ricerca””
- [19] “How Pinterest uses AI to capture our imaginations”
- [20] “How Lyft is using AI to keep customers happy”
- [21] “Using AI to detect cancer”
- [22] CapGemini, Digital Transformation Review 11 “Artificial Intelligence Decoded”
Articolo a cura di Alvaro Busetti

Alvaro Busetti opera come consulente free-lance e formatore. La sua vita professionale si è svolta nell’ambito dell’Information Technology con particolare riguardo agli aspetti progettuali e innovativi dal punto di vista organizzativo, applicativo e tecnologico. Ha svolto attività di conduzione progetti, coordinamento di unità produttive, attività di staff e supporto a livello Aziendale, di Gruppo e attività consulenziale per il top management del Cliente nel mercato dei Trasporti, Pubblica Amministrazione, Sanità, Industria, Servizi. Si è occupato di Intelligenza Artificiale, digital workplace e Office Automation, soluzioni Intranet, Sistemi multimediali, di Unified Communication e di Social Collaboration.





